Regulation of Gene Expression in Prokaryotes and Eukaryotes
While the period from 1900 to the Second World War has been
called the "golden age of genetics", we may be in a new golden (or
platinum) age. Recombinant DNA technology allows us to manipulate the very DNA
of living organisms and to make conscious changes in that DNA. Prokaryote
genetic systems are much easier to study and better understood than are
eukaryote systems.
Gene Regulation in
Prokaryotes
(1) In
Bacteria - The single chromosome of the common intestinal bacterium E. coli is circular and contains some
4.7 million base pairs. It is nearly 1 mm long, but only 2nm wide (Figure )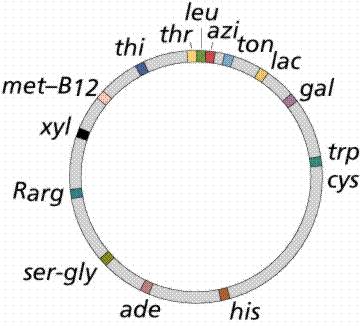
The
chromosome replicates in a bidirectional method, producing a figure resembling
the Greek letter theta. The promoter
is the part of the DNA to which the RNA polymerase
binds before opening the segment of the DNA to be transcribed.
A segment of the DNA that codes for a specific polypeptide
is known as a structural gene.
These often occur together on a bacterial chromosome. The location of the
polypeptides, which may be enzymes involved in a biochemical pathway, for
example, allows for quick, efficient transcription of the mRNAs. Often leader
and trailer sequences, which are not translated, occur at the beginning and end
of the region. E. coli can synthesize
1700 enzymes. Therefore, this small bacterium has the genes for 1700 different
mRNAs.
Lactose, milk sugar, is split by the enzyme β-galactosidase. This enzyme is inducible, since it occurs
in large quantities only when lactose, the substrate on which it operates, is
present. Conversely, the enzymes for the amino acid tryptophan are produced
continuously in growing cells unless tryptophan is present. If tryptophan is present
the production of tryptophan-synthesizing enzymes is repressed.
The Operon Model - The operon model (Figure) of prokaryotic gene
regulation was proposed by Fancois Jacob
and Jacques Monod. Groups of genes coding
for related proteins are arranged in units known as operons. An operon consists
of an operator, promoter, regulator, and structural genes. The regulator gene
codes for a repressor protein that binds to the operator, obstructing the
promoter (thus, transcription) of the structural genes. The regulator does not
have to be adjacent to other genes in the operon. If the repressor protein is
removed, transcription may occur.
Operons are either inducible or repressible
according to the control mechanism. Seventy-five different operons controlling
250 structural genes have been identified for E. coli. Both repression and induction are examples of negative
control since the repressor proteins turn off transcription.

Bacteria do not make all the proteins that they are capable
of making all of the time. Rather, they can adapt to their environment and make
only those gene products that are essential for them to survive in a particular
environment. For example, bacteria do not synthesize the enzymes needed to make
tryptophan when there is an abundant supply of tryptophan in the environment.
However, when tryptophan is absent from the environment the enzymes are made.
Similarly, just because a bacterium has a gene for resistance to an antibiotic
does not mean that that gene will be expressed. The resistance gene may only be
expressed when the antibiotic is present in the environment.
Bacteria usually control gene expression by regulating the
level of mRNA transcription. In bacteria, genes with related function are generally
located adjacent to each other and they are regulated coordinately (i.e. when
one is expressed, they all are expressed). Coordinate regulation of clustered
genes is accomplished by regulating the production of a polycistronic mRNA
(i.e. a large mRNA containing the information for several genes). Thus,
bacteria are able to "sense" their environment and express the
appropriate set of genes needed for that environment by regulating
transcription of those genes.
(A). INDUCIBLE GENES - THE OPERON MODEL
1. Definition
An
inducible gene is a gene that is expressed in the presence of a substance (an
inducer) in the environment. This substance can control the expression of one
or more genes (structural genes) involved in the metabolism of that substance.
For example, lactose induces the expression of the lac genes that are involved
in lactose metabolism. An certain antibiotic may induce the expression of a
gene that leads to resistance to that antibiotic.
Induction is common in metabolic pathways that result in
the catabolism of a substance and the inducer is normally the substrate for the
pathway.
2. Lactose Operon
a. Structural genes - The lactose operon (Figure 2.33) contains three structural
genes that code for enzymes involved in lactose metabolism.
- The lac z gene codes for β-galactosidase, an enzyme that breaks down
lactose into glucose and galactose
- The lac y gene codes for a permease, which is
involved in uptake of lactose
- The lac a gene codes for a galactose transacetylase.
These genes are transcribed from a common
promoter into a polycistronic mRNA, which is translated to yield the three
enzymes.
b. Regulatory gene - The expression of the structural genes is not only
influenced by the presence or absence of the inducer, it is also controlled by
a specific regulatory gene. The regulatory gene may be next to or far from the
genes that are being regulated. The regulatory gene codes for a specific
protein product called a REPRESSOR.
c. Operator - The repressor acts by binding to a specific region of the DNA called the
operator which is adjacent to the structural genes being regulated. The
structural genes together with the operator region and the promoter is called
an OPERON. However, the binding of the repressor to the operator is prevented
by the inducer and the inducer can also remove repressor that has already bound
to the operator. Thus, in the presence of the inducer the repressor is inactive
and does not bind to the operator, resulting in transcription of the structural
genes. In contrast, in the absence of inducer the repressor is active and binds
to the operator, resulting in inhibition of transcription of the structural
genes. This kind of control is referred to a NEGATIVE CONTROL since the
function of the regulatory gene product (repressor) is to turn off
transcription of the structural genes.
d. Inducer - Transcription of the lac genes is influenced by the
presence or absence of an inducer (lactose or other β-galactosides) (Figure 2.34).
e.g:- + inducer = expression and
- inducer = no expression

3. Catabolite repression
(Glucose Effect)
Many inducible operons are not only controlled by their
respective inducers and regulatory genes, but they are also controlled by the
level of glucose in the environment. The ability of glucose to control the
expression of a number of different inducible operons is called CATABOLITE
REPRESSION. Catabolite repression is generally seen in those operons which are
involved in the degradation of compounds used as a source of energy. Since
glucose is the preferred energy source in bacteria, the ability of glucose to
regulate the expression of other operons ensures that bacteria will utilize
glucose before any other carbon source as a source of energy.
Mechanism - There is
an inverse relationship between glucose levels and cyclic AMP (cAMP) levels in
bacteria. When glucose levels are high cAMP levels are low and when glucose
levels are low cAMP levels are high. This relationship exists because the
transport of glucose into the cell inhibits the enzyme adenyl cyclase which
produces cAMP. In the bacterial cell cAMP binds to a cAMP binding protein
called CAP or CRP. The cAMP-CAP complex, but not free CAP protein, binds to a
site in the promoters of catabolite repression-sensitive operons. The binding
of the complex results in a more efficient promoter and thus more initiations
of transcriptions from that promoter as illustrated in Figures 2.35 and 2.36.
Since the role of the CAP-cAMP complex is to turn on transcription this type of
control is said to be POSITIVE CONTROL. The consequences of this type of
control is that to achieve maximal expression of a catabolite repression
sensitive operon glucose must be absent from the environment and the inducer of
the operon must be present. If both are present, the operon will not be
maximally expressed until glucose is metabolized. Obviously, no expression of
the operon will occur unless the inducer is present.

(B). REPRESSIBLE GENES
- THE OPERON MODEL
1. Definition
Repressible genes are those in which the presence of a
substance (a co-repressor) in the environment turns off the expression of those
genes (structural genes) involved in the metabolism of that substance. e.g.,
Tryptophan represses the expression of the trp genes.
Repression is common in metabolic pathways that result in
the biosynthesis of a substance and the co-repressor is normally the end
product of the pathway being regulated.

2. Tryptophan operon
a. Structural genes - The tryptophan operon (Figure 2.37) contains five
structural genes that code for enzymes involved in the synthesis of tryptophan.
These genes are transcribed from a common promoter into a polycistronic mRNA,
which is translated to yield the five enzymes.

b. Regulatory gene - The expression of the structural genes is not only
influenced by the presence or absence of the co-repressor, it is also
controlled by a specific regulatory gene. The regulatory gene may be next to or
far from the genes that are being regulated. The regulatory gene codes for a
specific protein product called a REPRESSOR (sometimes called an apo-repressor).
When the repressor is synthesized it is inactive. However, it can be activated
by complexing with the co-repressor (i.e. tryptophan).
c. Operator - The active repressor /
co-repressor co-mplex acts by binding to a specific region of the DNA
called the operator which is adjacent to the structural genes being regulated.
The structural genes together with the operator region and the promoter is
called an OPERON. Thus, in the presence of the co-repressor the repressor is active
and binds to the operator, resulting in repression of transcription of the
structural genes. In contrast, in the absence of co-repressor the repressor is
inactive and does not bind to the operator, resulting in transcription of the
structural genes. This kind of control is referred to a NEGATIVE CONTROL since
the function of the regulatory gene product (repressor) is to turn off
transcription of the structural genes.
d. Co-repressor
- Transcription of the tryptophan
genes is influenced by the presence or absence of a co-repressor (tryptophan)
(Figure 2.38).
e.g.
:- + co-repressor = no
expression & - co-repressor = expression

Attenuation
In many
repressible operons, transcription that initiates at the promoter can terminate
prematurely in a leader region that precedes the first structural gene. (i.e.
the polymerase terminates transcription before it gets to the first gene in the
operon). This phenomenon is called ATTENUATION; the premature termination of
transcription. Although attenuation is seen in a
number of operons, the mechanism is best understood in those repressible
operons involved in amino acid biosynthesis. In these instances attenuation is
regulated by the availability of the cognate aminoacylated t-RNA.
Mechanism (See Figure 2.39)
- When transcription is initiated at the
promoter, it actually starts before the first structural gene and a leader
transcript is made. This leader region contains a start and a stop signal for
protein synthesis. Since bacteria do not have a nuclear membrane, transcription
and translation can occur simultaneously. Thus, a short peptide can be made
while the RNA polymerase is transcribing the leader region. The test peptide
contains several tryptophan residues in the middle of the peptide. Thus, if
there is a sufficient amount of tryptophanyl-t-RNA to translate that test
peptide, the entire peptide will be made and the ribosome will reach the stop
signal. If, on the other hand, there is not enough tryptophanyl-t-RNA to
translate the peptide, the ribosome will be arrested at the two tryptophan
codons before it gets to the stop signal.

The sequence in the leader m-RNA contains four regions,
which have complementary sequences (Figure 2.40). Thus, several different
secondary stem and loop structures can be formed. Region 1 can only form base
pairs with region 2; region 2 can form base pairs with either region 1 or 3;
region 3 can form base pairs with region 2 or 4; and region 4 can only form
base pairs with region 3. Thus three possible stem/loop structures can be
formed in the RNA.
region
1:region 2
region
2:region 3
region
3:region 4

One of the possible structures (region 3 base pairing with
region 4) generates a signal for RNA polymerase to terminate transcription
(i.e. to attenuate transcription). However, the formation of one stem and loop
structure can preclude the formation of others. If region 2 forms base pairs
with region 1 it is not available to base pair with region 3. Similarly if
region 3 forms base pairs with region 2 it is not available to base pair with
region 4.
The ability of the ribosomes to translate the
test peptide will affect the formation of the various stem and loop structures
Figure 2.41. If the ribosome reaches the stop signal for translation it will be
covering up region 2 and thus region 2 will not available for forming base
pairs with other regions. This allows the generation of the transcription
termination signal because region 3 will be available to pair with region 4.
Thus, when there is enough tryptophanyl-t-RNA to translate the test peptide
attenuation will occur and the structural genes will not be transcribed. In
contrast, when there is an insufficient amount of tryptophanyl-t-RNA to
translate the test peptide no attenuation will occur. This is because the
ribosome will stop at the two tryptophan codons in region 1, thereby allowing
region 2 to base pair with region 3 and preventing the formation of the
attenuation signal (i.e. region 3 base paired with region 4). Thus, the
structural genes will be transcribed.

(2) In Viruses Viruses
consist of a nucleic acid (DNA or RNA) enclosed in a protein coat (known as a capsid).
The capsid may be a single protein repeated over and over, as in tobacco mosaic
virus (TMV). It may also be several different proteins, as in the T-even bacteriophages.
Once inside the cell, the nucleic acid follows one of two paths: lytic or
lysogenic.
Retroviruses,
such as Human
Immuno-difficiency Virus (HIV), also include the enzyme reverse
transcriptase with the viral RNA. Reverse transcriptase makes a
single-stranded viral DNA copy of the single-stranded viral RNA. The single
stranded viral DNA is subsequently turned into a double-stranded DNA.
The lytic cycle occurs when the viral DNA immediately takes
over the host cell (remember that viruses are obligate intracellular parasites)
and begins making new viruses. Eventually the new viruses cause the rupture (or
lysis) of the cell, releasing those new viruses to continue the infection
cycle. The lysogenic cycle occurs when the viral DNA is incorporated into the
host DNA as a prophage. When the cell replicates the prophage is passed along
as if it were host DNA.
Sometimes the prophage can emerge from the host
chromosome and enter the lytic cycle spontaneously once every 10,000 cell
divisions. Ultraviolet light and x-rays may also trigger emergence of the
prophage. Transduction is the transfer of host DNA from one cell to another by
a virus (Figure 2.42). Some bacteriophages are temperate since they tend to go
lysogenic rather than lytic. These types of viruses are able to transduce
fragments of the host DNA.

Transposons
are DNA fragments incorporated into the chromosomal DNA (Figure 2.43). Unlike
episomes and prophages, transposons contain a gene producing an enzyme that
catalyzes insertion of the transposon at a new site. They also have repeated
sequences 20-40 nucleotides in length at each
end. Insertion sequences are short (600-1500 base pairs long) simple
transposons that do not carry genes beyond those essential for insertion of the
transposon into E. coli. Complex
transposons are much larger and carry additional genes. Genes incorporated in a
complex transposon are known as jumping genes since they can move about on the
chromosome (even from chromosome to chromosome). Often the complex transposons
are flanked by simple transposons.

Gene Regulation in Eukaryotes
In the absence of
precise information about the mechanisms that regulate gene expression in
eukaryotes, many models were proposed. One of the more popular early models
known as Britten Davidson model or Gene Battery model was that given by R.J. Britten and E.H. Davidson in 1969. This model even though widely accepted, is
only a theoretical model and lacks sound practical proof. The model predicts
the presence of four types of sequences.
Producer gene -
It is
comparable to a structural gene in prokaryotes. It produces pre mRNA, which
after processing becomes mRNA. Its expression is under the control of many
receptor sites.
Receptor site (gene) - It is comparable to the
operator in bacterial operon. At least one such receptor site is assumed to be
present adjacent to each producer gene. A specific receptor site is activated
when a specific activator RNA or an activator protein, a product of integrator
gene, complexes with it.
Integrator gene - Integrator gene is
comparable to regulator gene and is responsible for the synthesis of an
activator RNA molecule that may not give rise to proteins before it activates
the receptor site. At least one integrator gene is present adjacent to each
sensor site.
Sensor site - A
sensor site regulates activity of an integrator gene which can be transcribed
only when the sensor site is activated. The sensor sites are also regulatory
sequences that are recognized by external stimuli, e.g. hormones, temperature.
According to the Britten Davidson model, specific sensor genes represent
sequence-specific binding sites (similar to CAP-cAMP binding site in the E.
coil) that respond to a specific signal. When sensor genes receive the
appropriate signals, they activate the transcription of the adjacent integrator
genes. The integrator gene products will then interact in a sequence specific
manner with receptor genes.
Britten
and Davidson proposed that the integrator gene products are activator RNAs that
interact directly with the receptor genes to trigger the transcription of the
continuous producer genes.
It
is also proposed that receptor sites and integrator genes may be repeated a
number of times so as to control the activity of a large number of genes in the
same cell. Repetition of receptor ensures that the same activator recognizes
all of them and in this way several enzymes of one metabolic pathway are simultaneously
synthesized.
Transcription of the same gene may be needed in different
developmental stages. This is achieved by the multiplicity of receptor sites
and integrator genes. Each producer gene may have several receptor sites, each
responding to one activator. Thus, though a single activator can recognize
several genes, different activators may activate the same gene at different
times.
A set of structural genes controlled by one sensor site is
termed as a battery. Sometimes when major changes are needed, it is necessary
to activate several sets of genes. If one sensor site is associated with
several integrators, it may cause transcription of all integrators
simultaneously thus causing transcription of several producer genes through
receptor sites.
The repetition of integrator genes and receptor sites is consistent with
the reports that state that sufficient repeated DNA occurs in the eukaryotic
cells. The most attractive features of the Britten and Davidson model is that
it provides a plausible reason for the observed pattern of interspersion of
moderately repetitive DNA sequences and single copy DNA sequences.
Direct evidence indicates that most structural genes are indeed single
copy DNA sequences. The adjacent moderately repetitive DNA sequences would contain
the various kinds of regulator genes (sensor, integrator and receptor genes).
The latest estimates
are that a human cell, a eukaryotic cell, contains 20,000–25,000 genes.
- Some of these are expressed
in all cells all the time. These so-called housekeeping genes are
responsible for the routine metabolic functions (e.g. respiration) common
to all cells.
- Some are expressed as a cell enters a particular
pathway of differentiation.
- Some are expressed all the time in only those cells
that have differentiated in a particular way. For example, a plasma cell
expresses continuously the genes
for the antibody it synthesizes.
- Some are expressed only as conditions around and in
the cell change. For example, the arrival of a hormone may turn on (or
off) certain genes in that cell.
How is gene expression regulated?
There
are several methods used by eukaryotes.
- Altering the rate of transcription
of the gene. This is the most important and widely-used strategy and the
one we shall examine here.
- However, eukaryotes supplement transcriptional
regulation with several other methods:
o Altering
the rate at which RNA transcripts are processed while still within the nucleus.
o Altering
the stability of mRNA molecules; that is, the rate at which they are degraded.
Protein-coding
genes have
- exons
whose sequence encodes the polypeptide;
- introns that will be removed from the mRNA before it
is translated;
- a transcription start site
- a promoter
o the basal or core promoter located within about 40 bp of
the start site
o an "upstream" promoter, which may extend over as
many as 200 bp farther upstream
Adjacent
genes (RNA-coding as well as protein-coding) are often separated by an insulator
which helps them avoid cross-talk between each other's promoters and enhancers
(and/or silencers).
Transcription start
site This is where a molecule of RNA
polymerase II (pol II, also known as RNAP II) binds. Pol II is a
complex of 12 different proteins (shown in the figure in yellow with small
colored circles superimposed on it).
The basal promoter The basal promoter (Figure 2.44) contains a sequence of 7 bases
(TATA-AAA) called the TATA box. It is bound by a large complex of some 50
different proteins, including
- Transcription Factor IID (TFIID) which is a complex
of
o TATA-binding protein (TBP), which recognizes and binds to
the TATA box
o 14 other protein factors which bind to TBP — and each other
— but not to the DNA.
- Transcription Factor IIB (TFIIB) which binds both the
DNA and pol II.

The basal or core promoter is found in all protein-coding
genes. This is in sharp contrast to the upstream promoter whose structure and
associated binding factors differ from gene to gene.
Although the figure is drawn as a straight line, the
binding of transcription factors to each other probably draws the DNA of the
promoter into a loop.
Many different genes and many different types of cells
share the same transcription factors - not only those that bind at the basal
promoter but even some of those that bind upstream (Figure 2.45). What turns on
a particular gene in a particular cell is probably the unique combination of
promoter sites and the transcription factors that are chosen.

To open
any particular box in the room requires two keys:
- your key, whose pattern of notches fits only the lock
of the box assigned to you (= the
upstream promoter), but which cannot unlock the box without
- a key carried by a bank employee that can activate
the unlocking mechanism of any box (= the basal promoter) but cannot by
itself open any box.
|
Note : Transcription factors represent only a small fraction of the
proteins in a cell.
|
Hormones exert many of their effects by forming
transcription factors - The
complexes of hormones with their receptor represent one class of transcription
factor. Hormone "response elements", to which the complex binds, are
promoter sites.
Embryonic
development requires the coordinated production and distribution of
transcription factors.
Enhancers Some
transcription factors ("Enhancer-binding protein") bind to regions of
DNA that are thousands of base pairs away from the gene they control (Figure
2.46). Binding increases the rate of transcription of the gene.
Enhancers can be located upstream, downstream, or even
within the gene they control.
How does the binding of a protein to an enhancer regulate
the transcription of a gene thousands of base pairs away? One possibility
is that enhancer-binding proteins — in addition to their DNA-binding site, have
sites that bind to transcription factors ("TF") assembled at the
promoter of the gene. This would draw the DNA into a loop (as shown in the
figure 2.46).

Visual
evidence Michael
R. Botchan (who kindly supplied these electron micrographs) and his colleagues
have produced visual evidence of this model of enhancer action. They created an
artificial DNA molecule with
· several promoter sites
for Sp1 about 300 bases from one end. Sp1 is a zinc-finger
transcription factor that binds to the sequence 5' GGGCGG 3' found
in the promoters of many genes, especially "housekeeping" genes.
·
several enhancer sites
about 800 bases from the other end. These are bound by an enhancer-binding
protein designated E2.
·
1860 base pairs of DNA
between the two.
When these DNA molecules were added to a mixture of Sp1 and
E2, the electron microscope showed that the DNA was drawn into loops with
"tails" of approximately 300 and 800 base pairs.
At the neck of each loop were two distinguishable globs of
material, one representing Sp1 (red), the other E2 (blue) molecules. (The two
micrographs are identical; the lower one has been labeled to show the
interpretation.)
Artificial DNA molecules lacking either the promoter sites
or the enhancer sites, or with mutated versions of them, failed to form loops
when mixed with the two proteins.
Silencers Silencers are control regions of DNA that, like
enhancers, may be located thousands of base pairs away from the gene they control.
However, when transcription factors bind to them, expression of the gene they
control is repressed.
Insulators A problem: As you can see above,
enhancers can turn on promoters of genes located thousands of base pairs away.
What is to prevent an enhancer from inappropriately binding to and activating
the promoter of some other gene in the same region of the chromosome?
One
answer: an insulator.
Insulators
are
- stretches of DNA (as few as 42 base pairs may do the
trick)
- located between the
- enhancer(s) and promoter or
- silencer(s) and promoter
of adjacent
genes or clusters of adjacent genes.
Their function is to prevent a gene from being influenced
by the activation (or repression) of its neighbors.
Example: The
enhancer for the promoter of the gene for the delta chain of the gamma/delta
T-cell receptor for antigen (TCR) is located close to the promoter for the
alpha chain of the alpha/beta TCR (on chromosome 14 in humans) (Figure 2.47). A T cell must choose between one or
the other. There is an insulator between the alpha gene promoter and the delta
gene promoter that ensures that activation of one does not spread over to the
other.

All insulators discovered so far in vertebrates work only
when bound by a protein designated CTCF ("CCCTC binding factor";
named for a nucleotide sequence found in all insulators). CTCF has 11 zinc
fingers.
Another
example: In mammals (mice, humans, pigs), only the
allele for insulin-like growth factor-2 (IGF2) inherited from one's father is
active; that inherited from the mother is not — a phenomenon called imprinting.
The mechanism: the mother's allele has an insulator between
the IGF2 promoter and enhancer. So does the father's allele, but in his case,
the insulator has been methylated. CTCF can no longer bind to the insulator,
and so the enhancer is now free to turn on the father's IGF2 promoter.
Many of the commercially-important varieties of pigs have
been bred to contain a gene that increases the ratio of skeletal muscle
to fat. This gene has been sequenced and turns out to be an allele of IGF2,
which contains a single point mutation
in one of its introns. Pigs with this mutation produce higher levels of IGF2
mRNA in their skeletal muscles (but not in their liver).
This tells us that:
Mutations in non-coding portions of a gene can
affect how that gene is regulated (here, a change in muscle but not in liver).
Comments
Post a Comment